
2022 年 9 月 20 日晚間,輝達(Nvidia)舉辦的 2022 年度 GPU 技術會議(GTC)進行了全球同步直播,雖然這是針對於人工智慧、大數據、元宇宙、科學計算等開發人員的年度重要開發趨勢,對硬體玩家而言,這個直播,也是輝達的創辦人兼執行長:老黃 ─ 黃仁勳,發布新一代高階顯卡的日子。
在今年度的發表會上,對於喜愛微軟模擬飛行的玩家們,除了又有了新一代的顯卡能夠剁手以外,另一個重要的看點就是下面這段影片了。
影片中輝達展示了所謂新一代的 DLSS 3 技術,將MSFS的畫面流暢度提升了不僅僅只是百分之十或二十而已,而是近提高了一倍的每秒偵數,讓 MSFS 在未來終於有機會能擺脫偵數低落的惡夢。但為何新世代的40系列顯卡能有這麼強大的提升?讓我們看下去。
老黃:新一代的類神經即時光線追蹤渲染時代已經來臨。
在新一代所謂 40 系列的顯示卡,與上一代 30 系列相比,核心架構從原先的 Ampere 變更成為 Ada Lovelace,同時,40 系也應用了新的半導體工藝,不再使用三星 8N 製程,華裔出身的黃仁勳,這一次則轉向擁抱了台積電,並打算使用其嶄新的 4N 製程,進一步地推升輝達在顯示卡界的霸主地位。
而架構的改變,也代表著新的演算方式的出現。40 系列除了包含 Tensor 核心將升級到第四代外、RT 核心也升級至第三代,同時也納入了最重要一項革新技術的加入:著色器執行重排器(Shader Execution Reordering, SER)。
基本架構中的 RT 核心著重於加速即時光線追蹤計算,而第三代 RT 對於 Ray-triangle intersection 有兩倍以上的計算提升量,包含射線-三角相交計算,判斷射線是否與三角形面積有焦點,等同於光線碰觸計算物體是否需反射的計算,同時 RT 核心也增加了兩個新的硬體單元:Opacity Micromap Engine(透明度微圖引擎),加速光線幾何計算達前代2倍快;以及 Micro-Mesh Engine(微型網格引擎),能加速幾何豐富度並且不需 BVH (Bounding Volume Hierarchy 建置,用以確認遊戲中所需要互動到的物件計算範圍確認)及相關運算儲存成本。
Nvidia 顯示卡中的 Tensor 核心主要處理畫面處理的矩陣運算中心及相關深度學習模型。在第三代 Tensor 核心中,加入了 Hopper 架構中的 FP8 (8位元浮點精度) Transformer引擎,該引擎先前應用於 H100 人工智慧計算晶片之中,以達 到1.4Peta FLOPs(每秒浮點運算)的計算速度。
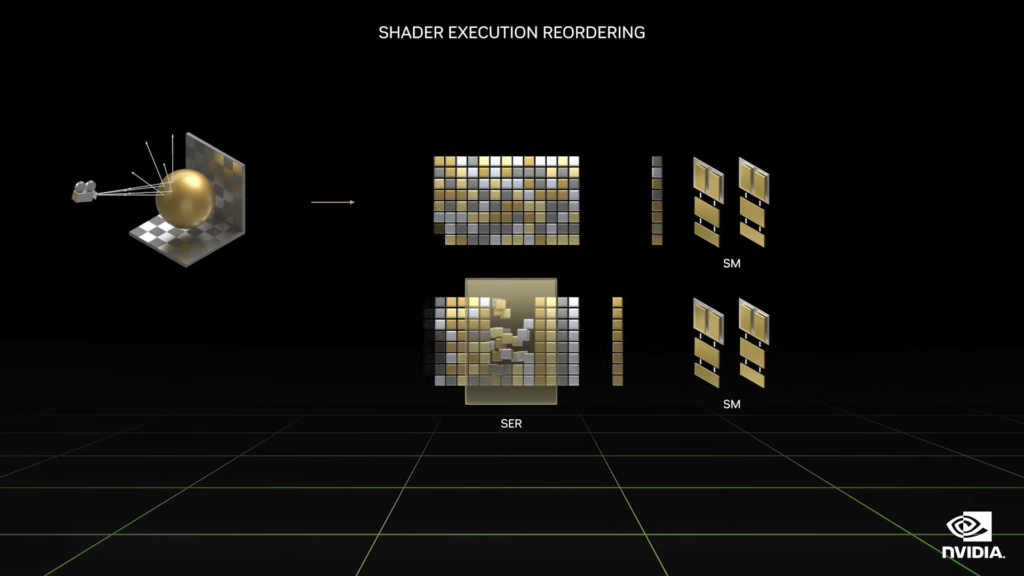
至於最重要的部分,就是這一代的 SM (streaming Multiprocessor, 串流複合處理器)單元,即最後圖形渲染計算單元,新增了著色器執行重排器(Shader Execution Reordering, SER),提升了光線追中的計算速度提升了2至3倍,並且新系列顯卡中將比前一代有兩倍的效能提升。
執行長黃仁勳也提到:光線追蹤的計算能力並不保證能夠導致高偵數的結果,因為光線各方向的反射及與各平面的交互互動,使得光線追蹤的計算難進行平行化計算。然而繪圖晶片 GPU 最強且最有效率的就是同時計算相似的工作,因此此次最重要的更新即為 SER 硬體及相關演算法的加入。在下圖中,我們可以看到圖層計算在光線追蹤的計算結果到由 SM 單元進行渲染前,經過 SER 進行重新排序再渲染,為了就是要讓 GPU 發揮更近似處理相似的工作,已達到 2 至 3 倍的光線追蹤計算速度提升以及 25% 遊戲效能提升成果。
Advertise
至於第三代深度學習超高取樣技術(DLSS 3),相較於前一代演算法也有些許的不同。先前的 RT 核心藉由 BVH 及 Ray-triangle intersection 的前運算,已減輕最後 SM 單元的計算量,但這樣的規劃對於高畫質、高動態的遊戲仍有很大的計算壓力。
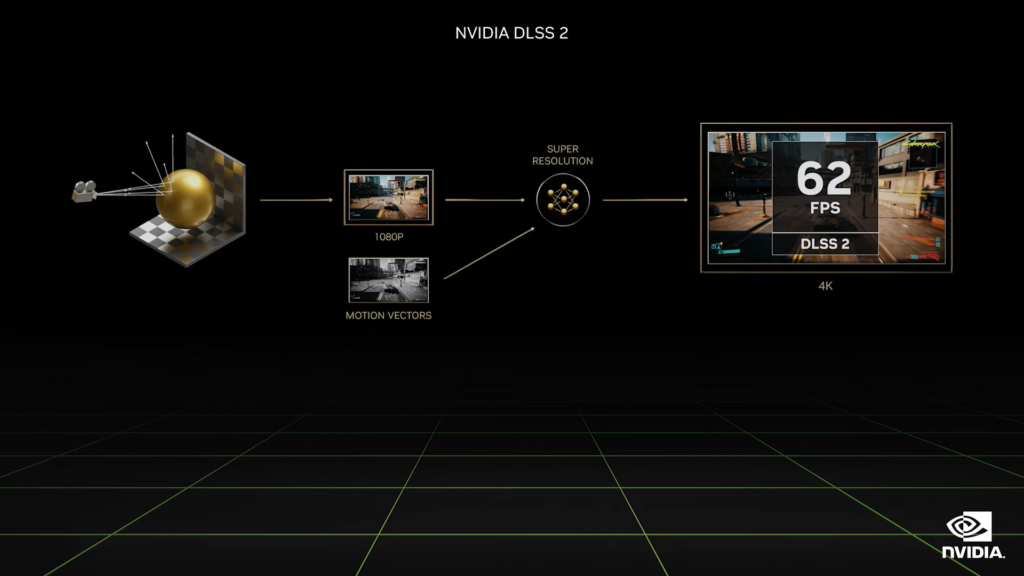
第二代 DLSS 主要利用人工智慧模型進行摺積自動編碼器計算,讓畫面以較低畫質(1080p)進行取樣,再與前一畫格高畫質(2K或4K)像進行動態向量差異運算,並藉由深度學習的方法,產生一個個畫素推算並把目前畫面補算回所需的畫質。而由於人工智慧模型已經被訓練為算回 16K 超高解析度畫面做為參考,再與計算的結果差異丟回神經網路進行訓練。
至於第三代的 DLSS 技術,新的模型輸出已經不再是產生一個個畫素,而是藉由新的 Optical Flow Accelerator(光學流加速器)、Game Engine Motion Vector(遊戲引擎動態向量)、Convolutional Autoencoder AI frame generator(摺積式自動編碼器人工智慧影格產生器)與 Reflex super-low-latency pipeline(Reflex 超低延遲流水線)等技術,直接進行整個影格的推算,換句話說,DLSS 3.0 主要計算新影格(new frame)及前一影格(prior frame)的差異來理解場景畫面的變化。
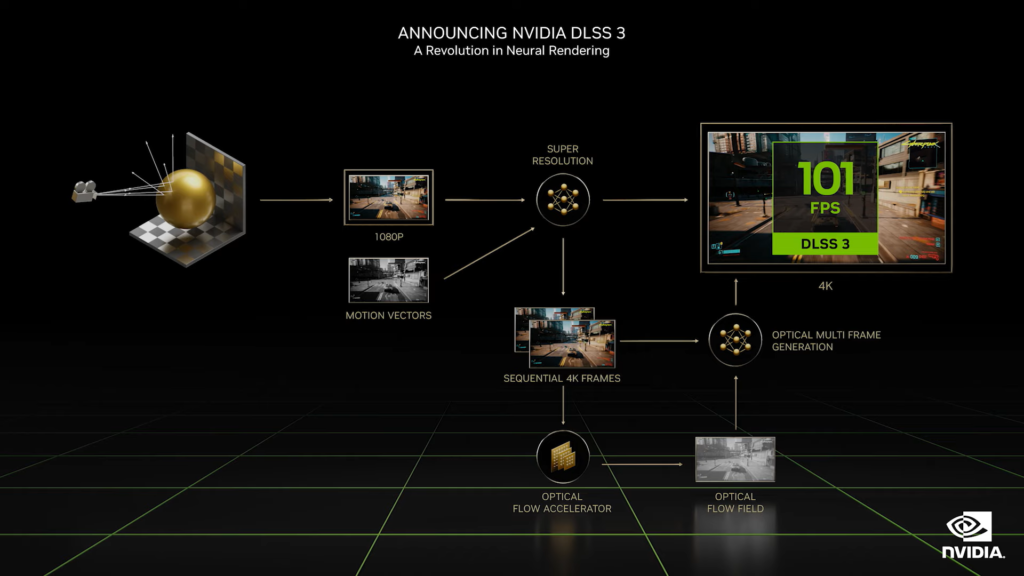
而 Optical Flow Accelerator 光學流加速器的加入,藉由影格之間的像素方向、速度資訊,丟入神經網路計算後,產生中間影格(intermediate frame),不需要原先的暴力圖像流水線的整套計算渲染,簡單來說,就是讓 GPU 去執行腦補的這項工作,進而推升遊戲的效能運算。
同時,這項技術對於以往 CPU 負荷較大如物理計算比重高或大型開放世界的遊戲類別來說,DLSS 3.0亦可以藉由新架構去進行 CPU 難以負荷的渲染計算,並且從最先光線追蹤只能計算每像素 39 條光線追蹤,進步到每像素 635 條光線追蹤。
而這項技術的應用主旨,正好完全貼合了微軟模擬飛行的設計內容:物理計算,以及超大型開放世界,因此才能夠在像展示影片之中般呈現出接近一倍偵數提升的比較效果。

也許有些人會想知道,DLSS 3技術是否能支援前幾代的顯卡型號?根據 Nvidia 應用深度學習研究院的副總Bryan Catanzaro表示:DLSS 3 將無法支援 30 系列及 20 系列。雖然第三代技術中的光學流加速器在先前 RTX 16 及 20 系列的圖靈架構就已經存在,但是由於 40 系列的架構、製程、以及演算流程的不同,就算讓舊型號執行 DLSS 3 技術,也會造成更差的體驗,並且不會改進 FPS。
不過沒有購買新顯卡打算的玩家也不必氣餒,目前也有部分支援 DLSS 3.0 的遊戲,能夠讓舊製程的顯卡應用DLSS 2 與 Reflex 的方式達到類似的提升效果。
Advertise
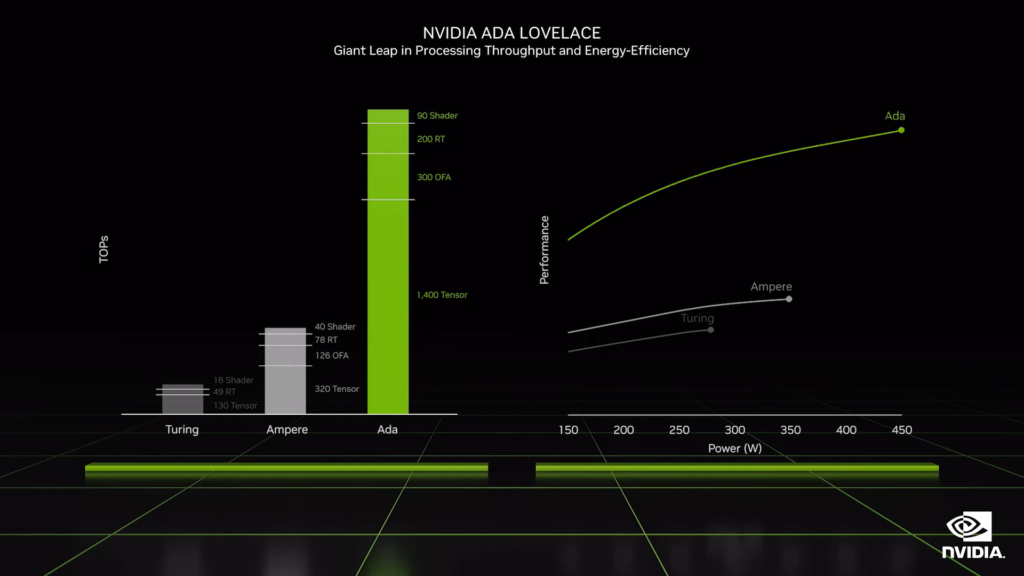
最後,不免俗的要附上新舊架構的性能比較表,顯而易見的具有效能上的提升,但功耗也是無可避免地往上提升了一大截,來到逼近 450W 的功耗,因此玩家要更換顯示卡之前,還是得好好思考電供是否能負擔的起這新款的吃電怪獸。
另外,玩家們最想知道莫過於 40 系列顯卡的建議售價(MSRP)到底是多少,而老黃又將會在新系列之中如何發揮他精湛的刀工技術?在發表會的當下,輝達一共發布了三款 40 系列顯示卡建議售價與發售日如下:
- RTX 4090:$1599 美元,2022 年 10 月 12 日起發售
- RTX 4080-16G:$1199 美元,2022 年 11 月發售
- RTX 4080-12G:$899 美元,2022 年 11 月發售


從基底架構的更換、先進的製程工藝、核心加入新單元、以及新演算法等所有集大成之新一代 RTX 40 系列顯卡,各位玩家們準備好要掏出神奇小卡把錢錢變成喜歡的模樣了?
又或者是你是等等黨,秉持著你不買,我不買,明天降兩百的心態,等著撿修正價格後的舊一代 30 系列顯卡的便宜呢?
最後不免俗地還是要說一句:TSMC Yes!
